When a bash command is run it usually gets run in a single thread. This means that it will all the processing work will get executed on a single CPU. As CPU’s have scaled out and increased their core count this means that only a small fraction of the available CPU resources will get used to work on your process.
These unused CPU resources can make a big difference when the work we are trying to get done is bound by the speed that the CPU can crunch the data. This typically happens during media conversion e.g. picture and video, and data compression.
In this guide, we will look at using the bash program Parallel. Parallel works by accepting a list as input and then executing a command in parallel across all your CPU cores on that list. Parallel will even send any output to stdout in sequence so it can be piped as stdin for a further command.
Update: I’ve written an accompanying guide on naively using parallel to send jobs out to remote machines to use all of their cores here.
How To Use Parallel
Parallel takes a list as input on stdin and then creates a number of processes with a supplied command, this takes the form:
list | parallel command
The list can be created by any of the usual bash commands e.g. cat, grep, find. The results of these commands are piped from their stdout to the stdin of parallel e.g.:
find . -type f -name "*.log" | parallel
Just like using -exec with find, parallel substitutes each member in the input list as {}. Here, parallel will gzip every file that find outputs:
find . -type f -name "*.log" | parallel gzip {}
The following examples of parallel in action will make this easier to understand.
Using Parallel For JPEG Optimization
In this example, I took a collection of largish .jpg, ~10MB files and ran them through the MozJPEG JPEG image optimization tool produced by Mozilla. This tool reduces JPEG image file size while attempting to retain the image quality. This is important for websites in order to keep page load times down.
Here is a typical find command to locate every .jpg file in the current directory and then run them through the image compression tool supplied in the MozJPEG package, cjpeg:
find . -type f -name "*.jpg" -exec cjpeg -outfile LoRes/{} {} ';'
This took 0m44.114s seconds to run. Here is what top looked like while it was running:
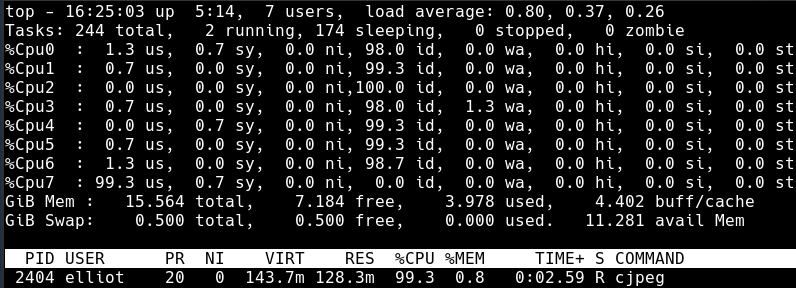
As you can see, only a single of the 8 available cores is working on the single thread.
Here is the same command run with parallel:
find . -type f -name "*.jpg" | parallel cjpeg -outfile LoRes/{} {}
This reduces the time to optimize all the images to 0m10.814s. The difference is clearly seen in this image of top:
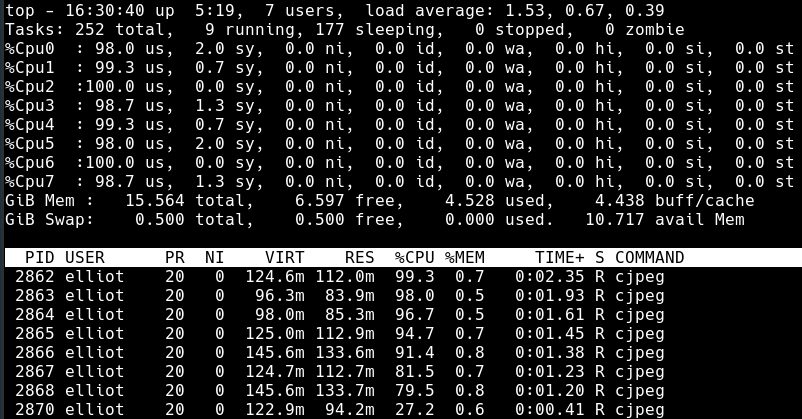
All the CPU cores are maxed out and there are 8 threads to match the 8 available CPU cores.
Using Parallel With GZIP
If you need to compress a number of files rather than a single large one then parallel will speed things up. If you do need to compress a single file and want to utilize all your CPU cores take a look at the multi-threaded gzip replacement pigz.
First, I created ~1GB of random data in 100 files:
for i in {1..100}; do dd if=/dev/urandom of=file-$i bs=1MB count=10; done
Then I compressed them using another find -exec command:
find . -type f -name "file*" -exec gzip {} ';'
This took 0m28.028s to complete and again only used a single core.
Converting the same command to use parallel gives us:
find . -type f -name "file*" | parallel gzip {}
This reduces the runtime to 0m5.774s.
Parallel is an easy to use tool that you should add to your sysadmins tool bag as it is going to save you a great deal of time in the right situation.